How to handle large datasets in Stata. Chapter 1, Memory
r(909); op. sys. refuses to provide memory
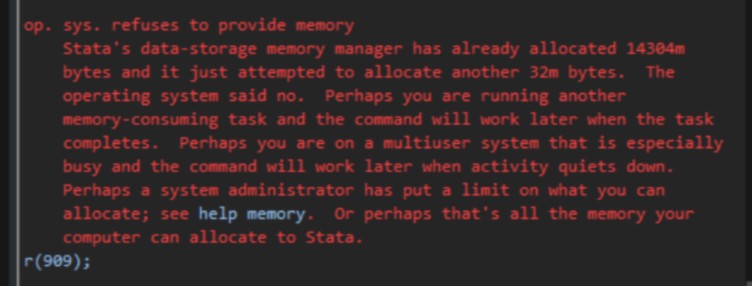 (Stata is not having a good time)
(Stata is not having a good time)
Introduction
If you are working with large datasets in Stata, memory tends to be a scarce resource.
It is also a very important resource—perhaps more important than you think—since insufficient memory can:
😐 slow down your code
😑 hog your hard drive
😒 prevent you from creating data..
😢 ..merging data..
😭 ..or even loading your data!
But don’t worry. Below you can find a bunch of tips and tricks that might help in these situations!
Before we start, I would encourage you to download my training dataset. The data file can be found here, or you can download it directly by parsing the code below into Stata.
. cd "<your preferred working directory>"
. copy "https://www.jankabatek.com/datasets/data.dta" data.dta
. ls
You can also make the dataset bigger:
. use "data.dta", clear
. expand 1000
. save "data.dta", replace
. /* this will yield a dataset with 100M observations */
Plus, if you want to run your own benchmarks, try my simplified timer library, tictoc:
. ssc install tictoc
. tic
. use "data.dta", clear
. toc
Tip.1 Work only with the data you need
If you are working with a massive dataset and you do not need all the information that is stored in it, make sure you load only the information that is relevant to you.
👉 Use only the subset of variables you need:
. use var1 var2 using "data.dta"
👉 Or the subset of observations you need:
. use "data.dta" if var1 != .
-
This proves particularly handy when the dataset is so big that Stata refuses to load it due to memory constraints.
-
If the subset is small, the dataset will also load much faster.
(the smaller the subset, the bigger the gains).
❌ But do NOT combine the two subsetting options in one command!
. use var1 using "data.dta" if var1 != .
- For some weird reason, this is much slower than loading the dataset in full (despite requiring less memory).
✔️ Better approach is to perform the subsetting operations in sequence:
. use var1 using "data.dta"
. keep if var1 !=.
/* or vice versa, the order of subsetting ops will likely make a difference! */
. use "data.dta" if var1 !=.
. keep var1
Click here to see other clever uses of subsetting
Other uses: 1. Variable Explorer
👉 To see which variables are stored in a big dataset, load just one observation:
. clear all
. use "data.dta" in 1
. /* 1 denotes the first observation */
. use "data.dta" in f
. /* f denotes the final (last) observation */
👉 FWIW, describe offers similar functionality:
. clear all
. describe using "data.dta"
/* The option varlist can come in handy, too! */
. describe using "data.dta", varlist
. di r(varlist)
✔️ both commands are blazing fast!
Other uses: 2. Sequential Processing
👉 When dealing with a dataset that is too big to load into Stata, you can split it into chunks that fit within your memory constraints, and process the data sequentially, one chunk at a time.
. use "data.dta" if random_id_number <= 500 , clear
. collapse (mean) var2, by(random_id_number)
. save "collapsed_chunk1.dta", replace
. use "data.dta" if random_id_number > 500 , clear
. collapse (mean) var2, by(random_id_number)
. append using "collapsed_chunk1.dta"
Tip 2. Store your data efficiently
👉 Always recast the data into appropriate data types (raw data can be stored in the craziest formats imaginable):
. use "data.dta", clear
. compress
👉 Next, familiarize yourself with Stata’s data types and declare them correctly when creating new variables:
. gen byte x = 12
. gen int y = 12345
. gen long z = 1234567890
. gen float f = 0.3
. gen double p = 3.1415926535898
You should know that non-integer numbers in Stata can be subject to sneaky—and arguably quite stupid—precision issues:
-
By default, Stata declares numerical variables in single-precision (float), but evaluates them in double-precision (double).
-
This leads to some paradoxical behaviors (click here for examples).
-
This can be avoided by declaring non-integer variables in double-precision (double), though they will take up twice as much memory.
👉 Do not store numerical variables as strings. Numbers typically require less memory than strings of numbers.
. describe year
. /* data.dta stores variable 'year' as a four-character string (str4) */
. destring year, replace
👉 For the same reason, variables storing calendar dates as strings should be converted into numerical datetime variables.
. describe birthday
/* data.dta stores variable 'birthday' as a YYYYMMDD string (str8) */
. gen int BD = date(birthday,"YMD")
/* Optional formatting command (useful for graphs and data browser) */
. format %td BD
/* Housekeeping: */
. drop birthday
-
Datetime variables require much less memory and they are much easier to handle.
-
They also serve as input into various useful date and time functions.
👉 Unless really needed, categorical string variables should be converted too:
. webuse census, clear
. describe state
. encode state, gen(state_num)
/* Housekeeping: */
. drop state
. compress state_num
Tip 3. Use random subsamples
👉 Whenever you are testing your workflows, running exploratory analyses, or doing anything else that does not require the full scope of your data, make sure you work with a small (preferably random) subsample:
. use "data.dta", clear
. sample 5
-
Subsampling will greatly speed up early stages of your projects!
-
You will be able to troubleshoot the data and code without having to wait for Stata to finish lengthy operations.
-
My recommendation is to move to full dataset operations only once it is clear that everything works as expected.
-
Fall back to subsampling if you’re making further changes to the model / data construction steps.
👉 Another major benefit of subsampling is that your work will be more friendly to the environment.1 Woohoo!!!
❌ But remember that the command sample is very slow. If you can, use the package randomtag instead. It proves 10x faster than sample in my benchmark simulations.
. ssc install randomtag
. use "data.dta", clear
. randomtag, count(1000) gen(t)
. keep if t == 1
. /* this samples 1000 observations */
🦥 If you’re lazy like me (and don’t care about randomization), you can keep only the first X observations:
. use "data.dta", clear
. keep in 1/1000
-
this proves 40x faster than sample, but the resulting subset isn’t random unless your full dataset is sorted by some randomized IDs.
-
Bear that in mind & exercise caution!
For hyperspeed, skip loading the full dataset entirely:
. use "data.dta" in 1/1000
Tip 4. Remember when creating new data is redundant
👉 In models with large sets of dummies, use factor variables instead of standalone dummies:
. sysuse nlsw88, clear
. reg wage i.occ i.ind age, robust
-
This can save crazy amounts of memory, since factorized dummies are not declared as variables in your dataset.
-
Or at least they are not declared all at once. I have not looked into the guts of the factorization commands, but I suspect some data creation is still going on. If you know more, send me an email!
👉 The same applies to lagged / leading / diff variables in time series or panel data contexts. Stata does need these variables to be generated and stored in your dataset.
. webuse sunspot
. tsset time
. reg spot l.spot l2.spot f1.spot d3.spot, robust
Tip 5. Make sure you have enough free disk space
Even if you follow all these recommendations, the model estimation may still require more memory than what your physical RAM offers.
When that happens, Stata starts relying on virtual memory (which means that it starts saving temporary files into the temporary folder located on your hard drive).
. display c(tmpdir)
- Try to avoid this at all costs, as it will render your code much slower
👉 If you can’t avoid it, make sure you have enough free disk space to accomodate the temporary files. Otherwise your estimation will likely result in error.
-
Annoyingly, the error occurs only when Stata runs out of disk space.
-
This means that the program might break when you are already hours (or days) into the estimation.
-
Further, depending on the model, the virtual memory files can prove absolutely massive (we’re talking tens or hundreds of GB).
So keep that in mind.
👉 You may also consider buying more RAM or moving the temporary folder to a bigger disk (preferably SSD).
Tip 6. Use frames (for Stata 16 and higher)
👉 To hold multiple datasets in memory, master the use of frames!
. sysuse auto, clear
. frame create ALT
. frame change ALT
. sysuse bplong, clear
. sum bp
. frame default: sum mpg
. frame change default
. sum mpg
. frame ALT: sum bp
-
Frames are a huge topic, and for the sake of this overview I will only point to the stuff I have already written.
-
You can check out this dedicated Twitter thread, or browse this slide deck for further details and examples.
👉 I will note that Stata devs need to develop the frames environment further to fully harness its potential.
Most of all, I would love to run regressions on a dynamic panel dataset while sourcing the values of static control variables from another (smaller) frame. Once again, the memory savings would be incredible.
Nevertheless, I still use Frames environments regularly as they give rise to big efficiency gains (more on this in the following chapters).
Post Script: 𝗥 versus Stata
Finally, an obligatory comment on 𝗥 🙏
𝗥 is great, but it struggles with large data frames, capping the maximum number of cells in a data frame at a fairly low number.
The cap is 2.1 billion (2,147,483,647), and I often find it to be binding.
- If you have a population of 220M, it only takes 10 variables to create a dataset that can’t be loaded into an 𝗥 data frame.
- Packages exist to bypass the cap, but you may face compatibility issues with other packages.
- Another potential solution is sequential processing.
Stata conveniently caps the maximum number of cells several orders higher.
The cap is 1.1 trillion (1,099,511,627,774), and it applies at the variable level.
- This means that, in theory, your dataset with 𝑘 variables can hold 𝑘-times 1 trillion cells, which is 💣
- Though good luck patching together enough RAM to load this beast!
Footnotes
-
To learn more about carbon footprint of (super)computing, see Stevens et al. (2020) ↩︎